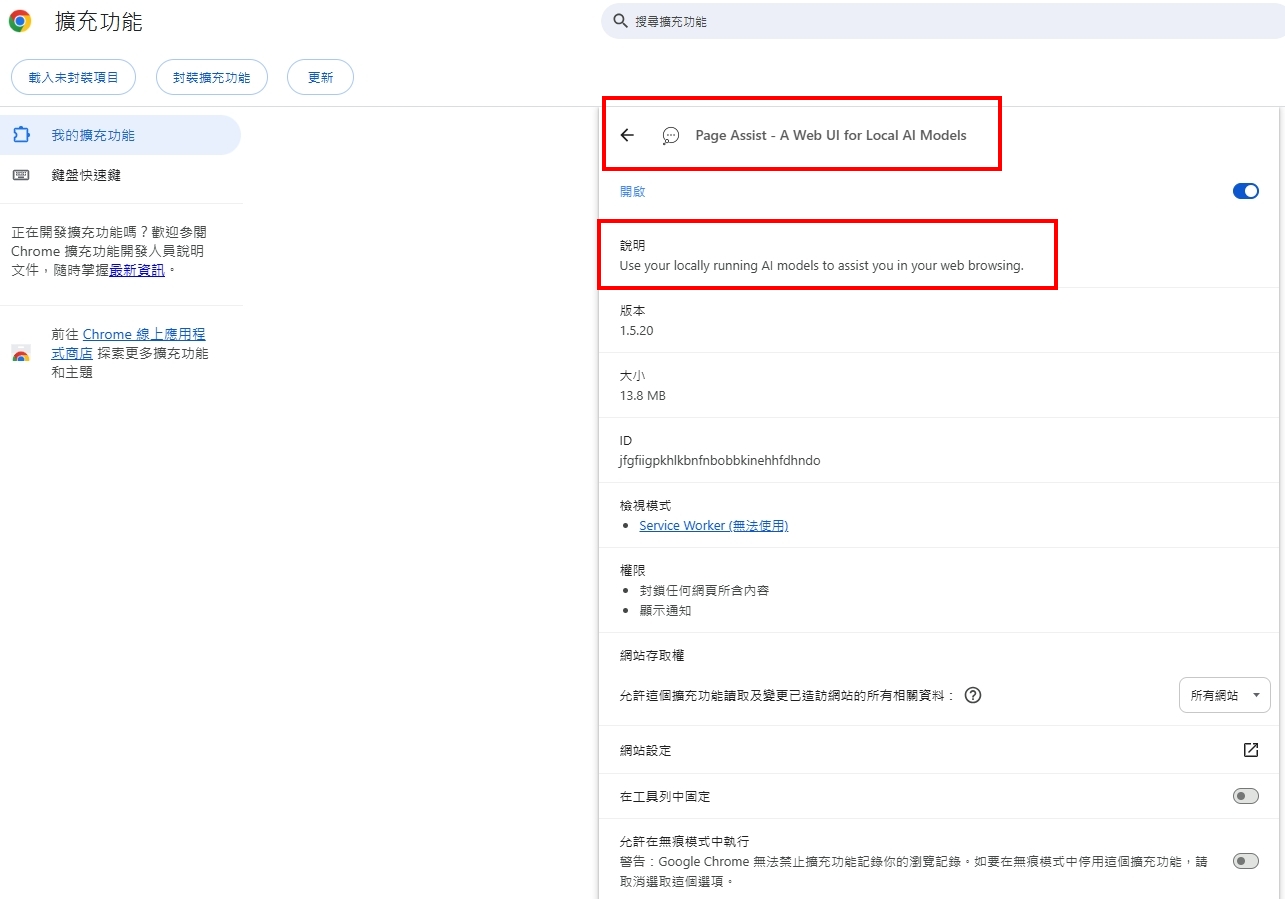
google chrome 有一擴充套件, 可供AI RAG本地知識庫應用使用, 各位有興趣者, 或可一試..

本來我是一直掛接本地llama大模型來使用, 今天試著將它掛接到外部的大模型, 比如deepseek V3版, 這可是一個完整版本的大模型, 雖然似乎它是較舊的版本, 但畢竟是個完整算力版, 我很意外的發現, 之前我的RAG, 準確度一直不穩定, 因為用的本地GPU, 最多也就能掛30B算力, RAG的準確度會飄移, 一會兒正常, 一會兒又不正常的, 目前外接這外部的大模型, 反倒一切都正常..目前還未發現回答不準確的問題..
但embedding model我還是掛接本地的, 所以ollama服務不能停..這樣的應用,优點是使用外部算力大的模型, 但資料仍然留在本地端知識庫,所以理論上,資料不會暴露在INTERNET才是.
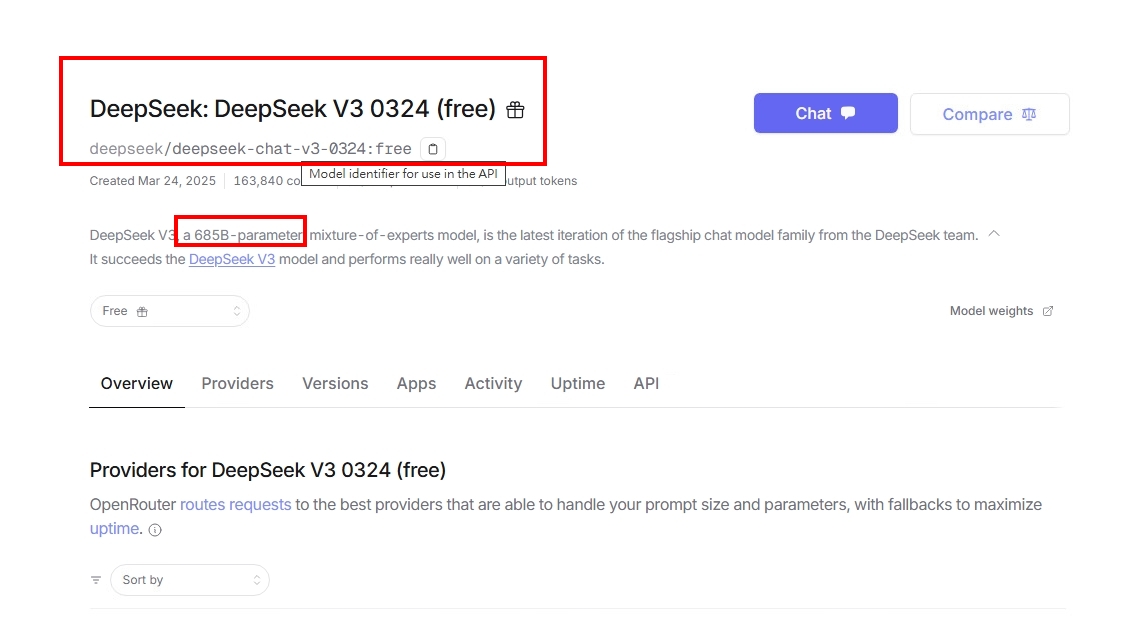
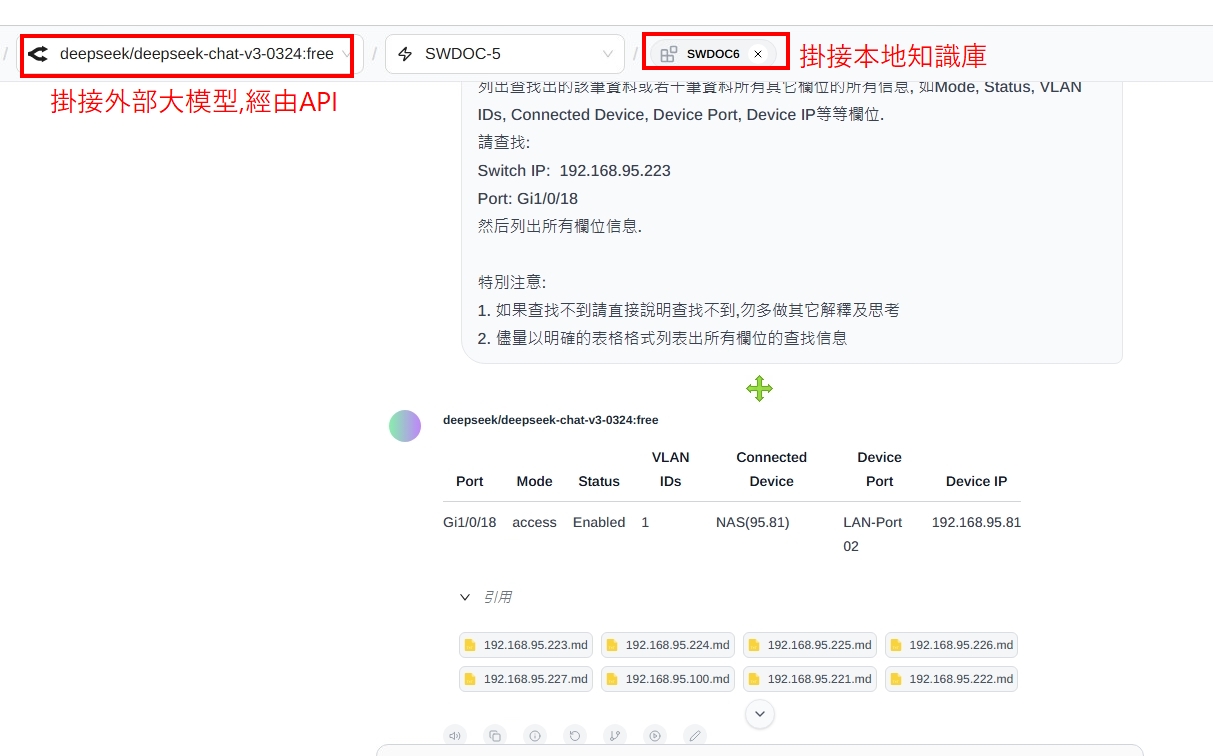
往常呢,我在這沒有GPU卡的VM上執行這些本地AI問答, 就算用最低算力1.5B, 回答也要等個十分鐘…目前改成掛接外部大模型, 基本一分鐘內就有回應, 且不像問本地時, 本機CPU也會高達100%, 目前看來這樣的應用是最為合適的使用方法了..而更重要的是回答的精準度比起之前要好太多..
以下是測試的影片, 實時錄製回應的時間..這個問答只耗費不到20秒..